
Współczesne aplikacje biznesowe budowane na platformie .NET coraz rzadziej przypominają proste programy typu CRUD. Wraz ze wzrostem skali i złożoności systemu kod, który "po prostu działa", przestaje wystarczać. Potrzebujemy kodu, który odzwierciedla rzeczywistą logikę biznesową, łatwo adaptuje się do zmian i posługuje się wspólnym językiem - zrozumiałym zarówno dla programistów, jak i ekspertów domenowych.
Z pomocą przychodzi Domain-Driven Design (DDD), czyli projektowanie zorientowane na domenę. DDD to nie tylko zestaw technik, ale przede wszystkim sposób myślenia o architekturze systemu, w którym to domena biznesowa gra pierwsze skrzypce. Dzięki takiemu nastawieniu jesteśmy w stanie przełożyć złożone wymagania biznesowe na modularny, zrozumiały kod - co znacząco ułatwia utrzymanie i rozwój dużych systemów.
W tym artykule przyjrzymy się praktycznemu zastosowaniu zasad DDD w świecie .NET. Omówię 3 kluczowe elementy: konteksty ograniczone (bounded contexts), agregaty oraz wzorzec repozytorium. Podzielę się też lekcjami z realnych projektów, które pokazują, jak dzięki DDD lepiej organizować kod, zachować spójność reguł biznesowych i unikać chaosu przy rozbudowie systemu.
Konteksty ograniczone: dziel i rządź domeną
Kontekst ograniczony (bounded context) to jedna z podstawowych koncepcji DDD, polegająca na wydzieleniu odrębnych obszarów biznesowych w ramach całego systemu. Zamiast budować jeden ogromny model obejmujący wszystkie aspekty biznesu, dzielimy domenę na mniejsze, bardziej zrozumiałe części. Każdy kontekst ma własne modele danych, logikę i znaczenie pojęć - obowiązujące tylko w jego granicach.
Przykładowo, w systemie e-commerce możemy wydzielić konteksty: Sprzedaż, Magazyn oraz Płatności. Pojęcie "Zamówienie" w kontekście Sprzedaży zawiera informacje o kliencie, zakupionych produktach i cenach. Z kolei w kontekście Magazynu "Zamówienie" będzie rozumiane jako lista przesyłek do skompletowania. Oddzielając te konteksty, unikamy nieporozumień - każdy zespół i moduł posługuje się swoim wspólnym językiem (tzw. ubiquitous language) i nie musi martwić się szczegółami spoza swojego zakresu.
Warto tu podkreślić rzecz, która często umyka: kontekst ograniczony to nie to samo co mikroserwis. To granica modelu i języka, a nie granica wdrożeniowa. Kilka kontekstów może z powodzeniem żyć w jednym monolicie (modularnym), a decyzję o wydzieleniu ich do osobnych serwisów można podjąć później, gdy realnie tego potrzebujemy.
Kluczowe jest też świadome zaprojektowanie relacji między kontekstami (tzw. context mapping). Rzadko są one całkowicie niezależne – zwykle jeden dostarcza danych drugiemu. Warto wtedy sięgnąć po sprawdzone wzorce:
• Anti-Corruption Layer (ACL) - warstwa tłumacząca model obcego kontekstu na nasz, tak by "obce" pojęcia nie przeciekały do naszej domeny. To jedno z najlepszych zabezpieczeń przed powolnym gniciem modelu.
• Shared Kernel - niewielki, świadomie współdzielony fragment modelu, którym opiekują się wspólnie dwa zespoły.
• Customer–Supplier - relacja, w której kontekst "dostawca" zobowiązuje się dostarczać to, czego potrzebuje kontekst "odbiorca".
Z doświadczenia wiem, że próby upchnięcia zbyt wielu funkcjonalności w jednym kontekście prędzej czy później kończą się plątaniną zależności i niejasnym modelem danych. Dlatego lepiej od początku podzielić system zgodnie z naturalnymi obszarami domenowymi i wyznaczyć zdrowe granice odpowiedzialności.
Główne zalety wyodrębniania kontekstów ograniczonych to:
• Lepsza spójność modeli - każdy kontekst ma własny model, dopasowany do swoich wymagań. Unikasz w ten sposób "przeładowanych" klas, które próbują obsłużyć wiele niepowiązanych ze sobą spraw naraz.
• Mniejsze sprzężenie między modułami - jasne granice ograniczają bezpośrednie zależności między częściami systemu. Zmiana w jednym kontekście rzadko wymusza zmiany w innym, co ułatwia równoległą pracę i testowanie.
• Autonomia i skalowalność - każdy moduł można rozwijać i skalować niezależnie. W architekturze mikroserwisów często jeden kontekst odpowiada jednemu serwisowi, co zwiększa autonomię zespołów i pozwala optymalizować każdy fragment systemu osobno.
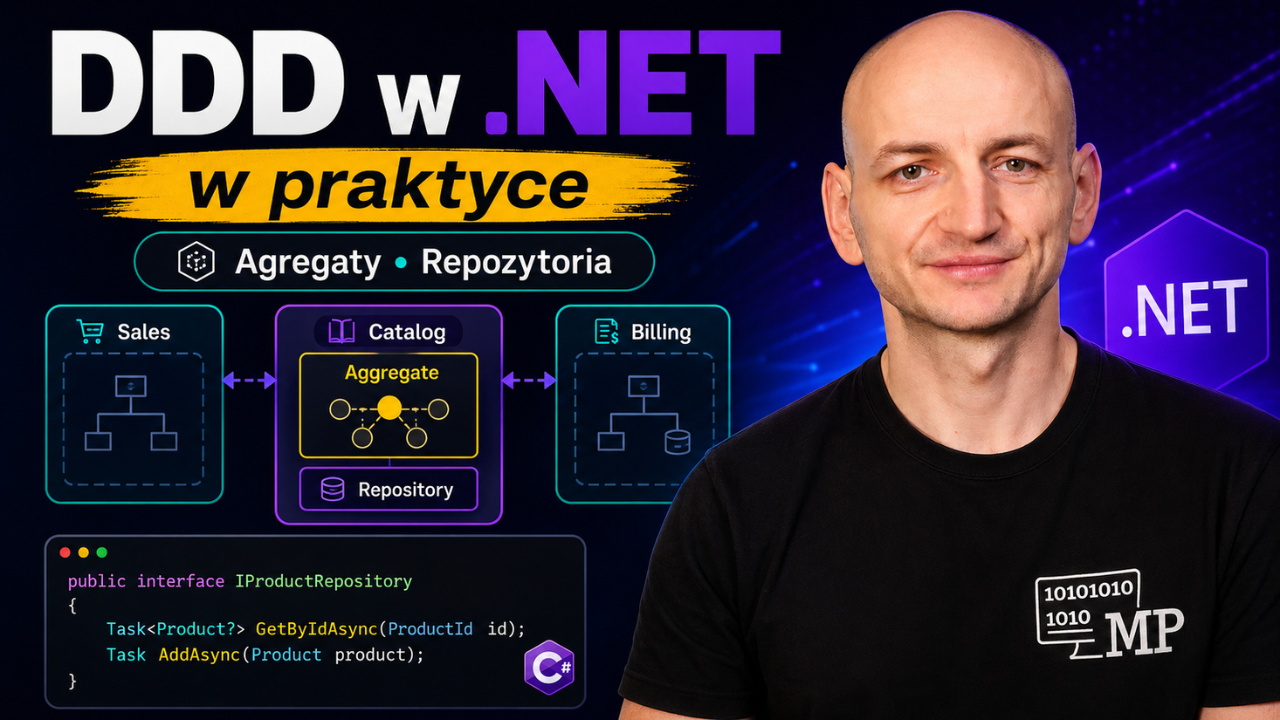
Agregaty domenowe: strażnicy spójności danych
W obrębie jednego kontekstu ograniczonego kluczową rolę odgrywają agregaty. Agregat to grupa powiązanych obiektów domenowych, które traktujemy jako jedną całość przy wykonywaniu operacji biznesowych. Każdy agregat posiada korzeń agregatu (Aggregate Root) - główny obiekt, przez który powinny przechodzić wszystkie modyfikacje danych wewnątrz agregatu.
Wyobraźmy sobie moduł zamówień. Agregatem może być obiekt Order, zawierający listę OrderItem. Zamówienie jako korzeń agregatu udostępnia metody do dodawania i usuwania pozycji, zmiany ich ilości itd. Dzięki temu wszelkie reguły biznesowe - przeliczanie łącznej ceny, sprawdzanie limitu wartości zamówienia - implementujemy wewnątrz agregatu. Inne części systemu (np. moduł fakturowania) nie manipulują bezpośrednio wewnętrznymi obiektami zamówienia. Zamiast tego wywołują publiczne metody korzenia.
Takie podejście gwarantuje utrzymanie inwariantów domenowych - zasad, które zawsze muszą być zachowane. Skoro cała modyfikacja stanu przechodzi przez korzeń agregatu, to on może dopilnować, by nie doszło do naruszenia reguł (np. nie pozwolić dodać ujemnej liczby produktów ani przekroczyć maksymalnej wartości zamówienia).
Oto jak taki agregat mógłby wyglądać w nowoczesnym C#. Zwróć uwagę na enkapsulację - kolekcja pozycji jest prywatna i wystawiona tylko do odczytu, a właściwości mają prywatne settery, więc stanu nie da się zmienić "z zewnątrz" z pominięciem reguł:
public class Order /* korzeń agregatu */
{
private readonly List<OrderItem> _items = new();
public IReadOnlyCollection<OrderItem> Items => _items.AsReadOnly();
public Guid Id { get; private set; }
public Guid CustomerId { get; private set; } /* referencja do innego agregatu PRZEZ ID */
public Money Total => new(_items.Sum(i => i.LineValue.Amount), "PLN");
public void AddProduct(Guid productId, int quantity, Money unitPrice)
{
if (quantity <= 0)
throw new ArgumentException("Ilość musi być dodatnia", nameof(quantity));
var existing = _items.FirstOrDefault(i => i.ProductId == productId);
if (existing is not null)
existing.IncreaseQuantity(quantity);
else
_items.Add(new OrderItem(productId, quantity, unitPrice));
}
}Przy okazji warto poznać dwa pojęcia, które w DDD chodzą z agregatami w parze:
• Obiekty wartości (value objects) - małe, niezmienne typy bez tożsamości, opisywane wyłącznie przez swoje wartości (np. Money, Address, Email). W C# świetnie sprawdzają się tu rekordy, które "za darmo" dają porównywanie po wartości i niezmienność:
public record Money(decimal Amount, string Currency);Zamiast przekazywać po systemie "gołe" decimal i string, opakowujemy je w typ, który sam pilnuje swoich reguł. To prosty sposób na walkę z tzw. primitive obsession.
• Zdarzenia domenowe (domain events) - informacja, że w domenie stało się coś istotnego (np. OrderPlaced). Agregat może je rejestrować u siebie, a inne części systemu reagują na nie już po zatwierdzeniu transakcji. To eleganckie spoiwo między agregatami i kontekstami, bez tworzenia sztywnych zależności.
Jest też jedna reguła, o której łatwo zapomnieć, a która potrafi uratować architekturę: agregaty odwołują się do siebie przez identyfikator, a nie przez referencję obiektu. Dlatego w przykładzie wyżej Order trzyma CustomerId typu Guid, a nie całego Customer. Dzięki temu granice agregatów pozostają wyraźne, a transakcje - małe i szybkie.
W praktyce warto też pilnować, by agregaty nie rozrastały się za bardzo. Częstym błędem jest zaprojektowanie jednego ogromnego agregatu obejmującego zbyt wiele encji. Taki "mega-agregat" bywa trudny w utrzymaniu i powoduje problemy wydajnościowe (np. blokady w bazie, gdy wiele operacji próbuje jednocześnie modyfikować różne części tego samego agregatu). Dobrą heurystyką jest pytanie: czy te elementy domeny zawsze zmieniają się razem? Jeśli nie - prawdopodobnie powinny należeć do osobnych agregatów.
Kilka dobrych praktyk przy projektowaniu agregatów:
• Jedna transakcja = jeden agregat - operacje, które muszą być atomowe, powinny dotyczyć pojedynczego agregatu. Ułatwia to utrzymanie spójności bez kosztownych transakcji rozproszonych.
• Ograniczony zakres odpowiedzialności - jeśli agregat robi się zbyt duży lub ma wiele niepowiązanych zadań, rozważ podział. Lepiej mieć kilka mniejszych, wyspecjalizowanych agregatów niż jeden odpowiedzialny za wszystko.
• Logika domenowa wewnątrz modeli - umieszczaj reguły w metodach obiektów domenowych, a nie w "anemicznych" usługach operujących na surowych danych. Dzięki temu reguły są egzekwowane w jednym miejscu, co zmniejsza ryzyko błędów.
Wzorzec Repozytorium: dostęp do danych w stylu DDD
Aby warstwa domenowa (nasze modele i logika biznesowa) pozostała niezależna od technologii przechowywania danych, DDD korzysta z wzorca Repozytorium. Repozytorium to pośrednik zapewniający dostęp do agregatów (poprzez ich korzenie) przechowywanych w bazie danych lub innym magazynie, ukrywając przed resztą systemu techniczne szczegóły zapisu i odczytu.
Ważna zasada: repozytorium tworzymy dla korzenia agregatu, a nie dla każdej encji z osobna. Nie ma sensu repozytorium OrderItemRepository - pozycje zamówienia pobieramy i zapisujemy zawsze przez Order.
Na platformie .NET zwykle definiujemy interfejsy repozytoriów w warstwie domenowej, a ich implementacje w warstwie infrastruktury (np. na Entity Framework Core, Dapperze albo API innego systemu). Domenie wystarczy wiedzieć, że może pobrać agregat po identyfikatorze albo zapisać zmiany – jak to się stanie, to już zadanie infrastruktury.
W nowoczesnym .NET dostęp do danych jest asynchroniczny, więc interfejs również powinien być asynchroniczny:
ppublic interface IOrderRepository
{
Task<Order?> GetByIdAsync(Guid id, CancellationToken ct = default);
Task AddAsync(Order order, CancellationToken ct = default);
void Update(Order order); /* śledzenie zmian po stronie ORM-a */
}Implementacja może używać Entity Framework Core lub bezpośrednio SQL – dla warstwy domenowej jest to transparentne. Zwróć uwagę, że w interfejsie nie ma metody Save() zapisującej pojedynczy agregat: właściwy commit transakcji to zwykle zadanie wzorca Unit of Work (w EF Core rolę tę pełni DbContext.SaveChangesAsync()), który zatwierdza wszystkie zmiany naraz i pilnuje reguły "jedna transakcja = jeden agregat".
Repozytoria ułatwiają też testowanie - w testach jednostkowych możemy podmienić prawdziwe repozytorium na atrapę w pamięci i sprawdzić logikę biznesową bez odwołań do zewnętrznej bazy.
Trzeba jednak pamiętać, by nie nadużywać tego wzorca. W prostych aplikacjach czysto CRUD-owych osobne warstwy abstrakcji bywają przerostem formy – czasem wystarczy bezpośrednio użyć DbContext z EF Core. Uważaj też na pokusę generycznego repozytorium (IRepository<T> ze wszystkimi metodami dla wszystkiego) – zwykle zaciera ono granice agregatów i wystawia operacje, których dana domena wcale nie potrzebuje. Przy złożonej logice biznesowej dedykowane repozytoria okazują się jednak niezastąpione: porządkują dostęp do danych i dają swobodę zmiany technologii przechowywania bez naruszania kodu domenowego.
Podsumowanie
Projektowanie zorientowane na domenę stawia na pierwszym miejscu zrozumienie i odwzorowanie logiki biznesowej w kodzie. Konteksty ograniczone pomagają okiełznać złożoność systemu poprzez podział na moduły odzwierciedlające poszczególne obszary biznesu. Wewnątrz tych modułów agregaty czuwają nad integralnością danych i egzekwowaniem reguł, a repozytoria zapewniają uporządkowany dostęp do trwałych danych, oddzielając warstwę biznesową od szczegółów technicznych. Taka architektura sprawia, że nawet duże systemy .NET pozostają przejrzyste, łatwe w modyfikacji i przygotowane na przyszły rozwój.
Oczywiście DDD to nie "srebrny pocisk" - w prostszych projektach pełne wdrożenie tych koncepcji bywa przerostem formy. Ale tam, gdzie domena jest złożona, a wymagania często się zmieniają, DDD procentuje, pozwalając uniknąć chaosu w architekturze na dalszych etapach rozwoju aplikacji.
Jeśli tego typu treści - konkretne, wyjęte z realnych projektów, a nie z podręcznikowych slajdów - są dla Ciebie wartościowe, to mam dla Ciebie coś jeszcze.
Prowadzę listę VIP, na której regularnie dzielę się praktyczną wiedzą o architekturze aplikacji .NET: wzorcami, które faktycznie sprawdzają się na produkcji, pułapkami, które łatwiej ominąć, gdy ktoś już raz się na nich przejechał, oraz materiałami, które nie trafiają na bloga. To miejsce dla programistów, którzy chcą pisać lepszy kod i świadomie rozwijać się w stronę architektury - bez lania wody, za to z rzeczami, które realnie przydają się w pracy.
Tutaj możesz dołączyć: modestprogrammer.pl/vip
Powodzenia w dalszym doskonaleniu umiejętności.

